Opened 3 years ago
Closed 3 years ago
#11 closed defect (fixed)
Set up backups
| Reported by: | chris | Owned by: | chris |
|---|---|---|---|
| Priority: | major | Milestone: | Install and configure crin1 |
| Component: | backups | Version: | |
| Keywords: | Cc: | jenny, gillian | |
| Estimated Number of Hours: | 6 | Add Hours to Ticket: | 0 |
| Billable?: | yes | Total Hours: | 18.47 |
Description
The plan is to use Advania S3 storage space (as GreenQloud is shutting down) and S3QL to backup the existing Servers at GreenQloud and also, on an on-going basis, Crin1 and Crin2.
Attachments (1)
Change History (41)
comment:1 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 1.5
- Total Hours set to 1.5
comment:2 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 1.25
- Total Hours changed from 1.5 to 2.75
Debian Wheezy (which web1.crin.org is running) has s3ql (1.11.1-3+deb7u1), there isn't a newer version available from backports and looking at the s3ql site it doesn't seem like compiling a new version would be a quick answer.
So mounting the live servers via SFTP and then using the new servers to upload the data to the S3 storage seems like the easiest thing to try.
On Crin1 create some mount points and mount db1.crin.org via SFTP:
cd /media mkdir db1.crin.org mkdir crin-gq-db1 aptitude install sshfs sshfs db1:/ db1.crin.org/
Create a script to mount this space at /usr/local/bin/mnt-sftp-db1, containing:
#!/bin/bash # http://fuse.sourceforge.net/sshfs.html sshfs db1:/ /media/db1.crin.org/
And one to unmount it at /usr/local/bin/umnt-sftp-db1, containing:
#!/bin/bash # http://fuse.sourceforge.net/sshfs.html fusermount -u /media/db1.crin.org
Create a S3 file system and mount it:
mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.db1 s3c://s.qstack.advania.com:443/crin-gq-db1 mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.db1 --allow-root s3c://s.qstack.advania.com:443/crin-gq-db1 /media/crin-gq-db1
Create a script to mount the S3QL storage space at /usr/local/bin/mnt-s3ql-db1 containing:
#!/bin/bash
# this scipt is for mounting a s3 compatible bucket using s3ql
# this is the name of the storageqloud bucket and also
# the local mount point under $MOUNT
BUCKET="crin-gq-db1"
# mount directory
MOUNT="/media"
# s3ql cache directory
CACHE="/var/s3ql"
# s3ql auth file
AUTH="/root/.s3ql/authinfo2.db1"
# s3ql server
SERVER="s3c://s.qstack.advania.com:443"
# check that the script is being run by root
if [[ "$(id -u)" != "0" ]] ; then
echo "You must run $0 as root or via sudo"
exit 2
fi
# if force is wanted for filesystem check
if [[ $1 == "--force" ]]; then
# file system check with force
fsck.s3ql --cachedir ${CACHE} --authfile ${AUTH} --force --batch ${SERVER}/${BUCKET} \
|| echo "Force filesystem check of ${SERVER}/${BUCKET} failed"
else
# file system check
fsck.s3ql --cachedir ${CACHE} --authfile ${AUTH} --batch ${SERVER}/${BUCKET} \
|| echo "Filesystem check of ${SERVER}/${BUCKET} failed"
fi
# mount the s3ql file system
mount.s3ql --cachedir ${CACHE} --authfile ${AUTH} \
--allow-root ${SERVER}/${BUCKET} ${MOUNT}/${BUCKET} || \
echo "Mounting ${SERVER}/${BUCKET} on ${MOUNT}/${BUCKET} failed"
exit 0
And one for unmounting at /usr/local/bin/umnt-sftp-db1
#!/bin/bash
# this scipt is for unmounting a s3 compatible bucket using s3ql
# this is the name of the storageqloud bucket and also
# the local mount point under /media
BUCKET="crin-gq-db1"
# mount directory
MOUNT="/media"
# s3ql cache directory
CACHE="/var/s3ql"
# s3ql auth file
AUTH="/root/.s3ql/authinfo2.db1"
# s3ql server
SERVER="s3c://s.qstack.advania.com:443"
# check that the script is being run by root
if [[ "$(id -u)" != "0" ]] ; then
echo "You must run $0 as root or via sudo"
exit 2
fi
# if force is needed
if [[ $1 == "--force" ]]; then
fusermount -u -z ${MOUNT}/${BUCKET}
killall -9 mount.s3ql
# file system check with force
fsck.s3ql --cachedir ${CACHE} --authfile ${AUTH} --batch --force ${SERVER}/${BUCKET}
else
# unmount
umount.s3ql ${MOUNT}/${BUCKET}
# check the file system
fsck.s3ql --cachedir ${CACHE} --authfile ${AUTH} --batch ${SERVER}/${BUCKET}
fi
exit 0
Create a script to backup the server at /usr/local/bin/backup-s3ql-db1 containing:
#!/bin/bash
# these two variables are different on different servers
BUCKET="crin-gq-db1"
BACKUP_DIRS="/media/db1.crin.org/var/backups/mysql/databases /media/db1.crin.org/root /media/db1.crin.org/etc /media/db1.crin.org/usr/local/sbin /media/db1.crin.org/home"
# mount directory
MOUNT="/media"
# base directory for backups
BACKUP_ROOT="${MOUNT}/${BUCKET}"
# the latest backup
BACKUP_LATEST="${BACKUP_ROOT}/latest"
DATE=$(date "+%Y-%m-%d_%H-%M")
YEAR=$(date "+%Y")
MONTH=$(date "+%m")
# archive of the latest backup
BACKUP_ARCHIVE="${BACKUP_ROOT}/${YEAR}/${MONTH}/$DATE"
# rsync command
#RSYNC="rsync -av --delete --timeout=120 --bwlimit=10000"
RSYNC="rsync -aq --delete --timeout=120 --bwlimit=10000"
# check that the script is being run by root
if [[ "$(id -u)" != "0" ]] ; then
echo "You must run $0 as root or via sudo"
exit 2
fi
# check that the s3ql file system is mounted
MOUNTED=$(df -h | grep ${BUCKET})
if [[ ! ${MOUNTED} ]]; then
echo "${BACKUP_ROOT} is not mounted"
# unmount s3ql filesystem with check to see of force is needed here
FORCE_UNMOUNT=$(umnt-s3ql 2>&1 | grep "Can not check mounted file system.")
# force is needed to unmount the s3ql file system
if [[ ${FORCE_UNMOUNT} ]]; then
echo "using force to unmount ${BACKUP_ROOT}"
umnt-s3ql-db1 --force
fi
# mount the s3ql filesystem
echo "Mounting ${BACKUP_ROOT}"
mnt-s3ql-db1
fi
# copy data to $BACKUP_LATEST
for d in ${BACKUP_DIRS}; do
# check the s3ql file system is still mounted
MOUNTED=$(df -h | grep ${BUCKET})
if [[ ${MOUNTED} ]]; then
echo "Starting backup of ${d}"
test -d ${BACKUP_LATEST}${d} || mkdir -p ${BACKUP_LATEST}${d} || exit 1
${RSYNC} ${d}/ ${BACKUP_LATEST}${d}/ || exit 1
echo "Completed backup of ${d}"
else
echo "${BACKUP_ROOT} is not mounted"
exit 1
fi
done
# copy $BACKUP_LATEST to $BACKUP_ARCHIVE and make it immutable
# make the parent directory for todays backup
test -d ${BACKUP_ROOT}/${YEAR}/${MONTH} || mkdir -p ${BACKUP_ROOT}/${YEAR}/${MONTH} || exit 1
# copy the latest backup to a directory based on the date
echo "Copying $BACKUP_LATEST to $BACKUP_ARCHIVE"
s3qlcp $BACKUP_LATEST $BACKUP_ARCHIVE || exit 1
# make the date based backup immutable
echo "Making $BACKUP_ARCHIVE immutable"
s3qllock $BACKUP_ARCHIVE || exit 1
echo "$0 Completed successfully"
exit 0
Install screen and try running it:
aptitude install screen screen backup-s3ql-db1
comment:3 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 2.75 to 2.9
That backup job ended and reported:
Starting backup of /media/db1.crin.org/var/backups/mysql/databases Completed backup of /media/db1.crin.org/var/backups/mysql/databases Starting backup of /media/db1.crin.org/root Completed backup of /media/db1.crin.org/root Starting backup of /media/db1.crin.org/etc Completed backup of /media/db1.crin.org/etc Starting backup of /media/db1.crin.org/usr/local/sbin Completed backup of /media/db1.crin.org/usr/local/sbin Starting backup of /media/db1.crin.org/home Completed backup of /media/db1.crin.org/home Copying /media/crin-gq-db1/latest to /media/crin-gq-db1/2015/05/2015-05-18_11-55 Making /media/crin-gq-db1/2015/05/2015-05-18_11-55 immutable ./backup-s3ql-db1 Completed successfully
So the backing up of all the live servers at GreenQloud can be done using this method, I'll sort that out tonight or tomorrow for the others.
Note the scripts above don't contain a check that the SFTP filesystem is mounted -- this should be added before running them via cron.
I also added s3ql.mount to the process memory tracking so we can keep an eye on this (it might be better to unmount the s3ql storage when it isn't being used), see crin1.crin.org :: multips memory.
comment:4 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.35
- Total Hours changed from 2.9 to 3.25
Mounting the GreenQloud live webserver, web1.crin.org using SFTP on Crin2:
sudo -i aptitude install s3ql sshfs mkdir /root/.s3ql chmod 700 /root/.s3ql touch /root/.s3ql/authinfo2.web1 chmod 600 /root/.s3ql/authinfo2.web1
Add the following to /root/.s3ql/authinfo2.web1:
[s3c] storage-url: s3c://s.qstack.advania.com:443/crin-gq-web1 backend-login: [API key] backend-password: [Secret key]
Format and mount it:
mkdir /var/s3ql chmod 700 /var/s3ql mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.web1 s3c://s.qstack.advania.com:443/crin-gq-web1 mkdir /media/crin-gq-web1 chmod 700 /media/crin-gq-web1 mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.web1 --allow-root s3c://s.qstack.advania.com:443/crin-gq-web1 /media/crin-gq-web1
Mount the server filesystem over SFTP:
mkdir /media/web1.crin.org sshfs web1:/ /media/web1.crin.org/
Create scripts as before, install screen and try running the backup:
aptitude install screen screen backup-s3ql-web1 Starting backup of /media/web1.crin.org/var/www
Will check on this later...
comment:5 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.9
- Total Hours changed from 3.25 to 4.15
Repeating the above to mount and backup the wiki.crin.org and web2.crin.org servers at GreenQloud via Crin1.
web2.crin.org and wiki.crin.org didn't have MySQL database dumps to backup, so on both servers:
aptitude install backupninja ninjahelper
Created a MySQL backup action, this will dump the MySQL databases every night into /var/backups/mysql/sqldump/ via the settings in /etc/backup.d/20.mysql.
The scripts were copied and then:
mnt-sftp-web2 mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.web2 s3c://s.qstack.advania.com:443/crin-gq-web2 mnt-s3ql-web2 screen backup-s3ql-web2 Starting backup of /media/web2.crin.org/root
Repeat for the wiki server:
mnt-sftp-wiki mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.wiki s3c://s.qstack.advania.com:443/crin-gq-wiki mnt-s3ql-wiki screen backup-s3ql-wiki
So, these all seem to be running OK, these are the filesystems we now have mounted on Crin2:
Filesystem Size Used Avail Use% Mounted on /dev/dm-0 121G 27G 89G 23% / udev 10M 0 10M 0% /dev tmpfs 793M 25M 769M 4% /run tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup /dev/sda1 236M 33M 191M 15% /boot s3c://s.qstack.advania.com:443/crin-gq-web1 1.0T 390M 1.0T 1% /media/crin-gq-web1 web1:/ 9.4G 1.5G 7.4G 17% /media/web1.crin.org
And on Crin1:
Filesystem Size Used Avail Use% Mounted on /dev/dm-0 121G 9.9G 105G 9% / udev 10M 0 10M 0% /dev tmpfs 793M 33M 761M 5% /run tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup /dev/sda1 236M 33M 191M 15% /boot s3c://s.qstack.advania.com:443/crin-1984-crin1 1.0T 0 1.0T 0% /media/crin-1984-crin1 db1:/ 9.4G 2.3G 6.6G 26% /media/db1.crin.org s3c://s.qstack.advania.com:443/crin-gq-db1 1.0T 3.1G 1021G 1% /media/crin-gq-db1 web2:/ 153G 2.8G 143G 2% /media/web2.crin.org s3c://s.qstack.advania.com:443/crin-gq-web2 1.0T 47M 1.0T 1% /media/crin-gq-web2 wiki:/ 18G 1.9G 16G 11% /media/wiki.crin.org s3c://s.qstack.advania.com:443/crin-gq-wiki 1.0T 90M 1.0T 1% /media/crin-gq-wiki
Assuming the backup jobs run OK the following tasks are to still to be done on this ticket:
comment:6 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 4.15 to 4.3
The wiki backup appears to have failed, this is the result:
Starting backup of /media/wiki.crin.org/var/backups Completed backup of /media/wiki.crin.org/var/backups Starting backup of /media/wiki.crin.org/root Completed backup of /media/wiki.crin.org/root Starting backup of /media/wiki.crin.org/etc Completed backup of /media/wiki.crin.org/etc Starting backup of /media/wiki.crin.org/usr/local/sbin Completed backup of /media/wiki.crin.org/usr/local/sbin Starting backup of /media/wiki.crin.org/home Completed backup of /media/wiki.crin.org/home Copying /media/crin-gq-wiki/latest to /media/crin-gq-wiki/2015/05/2015-05-18_17-38 Making /media/crin-gq-wiki/2015/05/2015-05-18_17-38 immutable File system appears to have crashed.
The web2 backup is still running:
Completed backup of /media/web2.crin.org/root Starting backup of /media/web2.crin.org/home Completed backup of /media/web2.crin.org/home Starting backup of /media/web2.crin.org/etc Completed backup of /media/web2.crin.org/etc Starting backup of /media/web2.crin.org/var/www Completed backup of /media/web2.crin.org/var/www Starting backup of /media/web2.crin.org/var/backups Completed backup of /media/web2.crin.org/var/backups Copying /media/crin-gq-web2/latest to /media/crin-gq-web2/2015/05/2015-05-18_17-26
From the firewall traffic it looks like things are still happening
The web1 backup on Crin2 is also still running:
Starting backup of /media/web1.crin.org/var/www
But it looks like it is still running based on the firewall stats.
I'll check back on progress later today or tomorrow, the initial backup is bound to be slower that subsequent ones.
comment:7 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 1
- Total Hours changed from 4.3 to 5.3
Just had this in the logwatch email from Crin1:
--------------------- Disk Space Begin ------------------------ df: '/media/crin-gq-web2': Transport endpoint is not connected df: '/media/crin-gq-wiki': Transport endpoint is not connected Filesystem Size Used Avail Use% Mounted on /dev/dm-0 121G 9.7G 105G 9% / udev 10M 0 10M 0% /dev /dev/sda1 236M 33M 191M 15% /boot s3c://s.qstack.advania.com:443/crin-1984-crin1 1.0T 0 1.0T 0% /media/crin-1984-crin1 db1:/ 9.4G 2.3G 6.6G 26% /media/db1.crin.org s3c://s.qstack.advania.com:443/crin-gq-db1 1.0T 3.1G 1021G 1% /media/crin-gq-db1 web2:/ 153G 2.8G 143G 2% /media/web2.crin.org wiki:/ 18G 1.9G 16G 11% /media/wiki.crin.org df: '/media/crin-gq-web2': Transport endpoint is not connected df: '/media/crin-gq-wiki': Transport endpoint is not connected ---------------------- Disk Space End -------------------------
On Crin1, the two jobs running in screen have ended, both with:
File system appears to have crashed.
So:
umnt-s3ql-web2
File system appears to have crashed.
Can not check mounted file system.
umnt-s3ql-web2 --force
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-web2
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 9500 objects so far..Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 3-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 4-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 5-th time...
..processed 18000 objects so far..Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to Backend.delete for the 3-th time...
Deleted spurious object 5589
Deleted spurious object 7869
Checking objects (sizes)...
Object 9558 has no size information, retrieving from backend...
Object 10557 has no size information, retrieving from backend...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to Backend.get_size for the 3-th time...
Object 15692 has no size information, retrieving from backend...
Object 15694 has no size information, retrieving from backend...
Object 16457 has no size information, retrieving from backend...
Object 16594 has no size information, retrieving from backend...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.11.1', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1213, in main
dump_metadata(db, fh)
File "/usr/lib/s3ql/s3ql/metadata.py", line 149, in dump_metadata
dump_table(table, order, columns, db=db, fh=fh)
File "s3ql/deltadump.pyx", line 317, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:4314)
File "s3ql/deltadump.pyx", line 364, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:3963)
ValueError: Can't dump NULL values
umnt-s3ql-web2
/media/crin-gq-web2 is not on an S3QL file system
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-web2
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 16500 objects so far..Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 3-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 4-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 5-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 6-th time...
..processed 17500 objects so far..Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 3-th time...
Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 4-th time...
..processed 18000 objects so far..
Checking objects (sizes)...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.11.1', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1213, in main
dump_metadata(db, fh)
File "/usr/lib/s3ql/s3ql/metadata.py", line 149, in dump_metadata
dump_table(table, order, columns, db=db, fh=fh)
File "s3ql/deltadump.pyx", line 317, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:4314)
File "s3ql/deltadump.pyx", line 364, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:3963)
ValueError: Can't dump NULL values
After some searching I found someone else with an issue like this, but their problem seems to be to relate to the use of NFS, the issues might relate to the S3 storage consistency window, perhaps this needs to be raised with Advania, also I wonder if setting the tcp-timeout migth help since the error is send/recv timeout exceeded, perhaps this needs raising as a s3ql issue.
Perhas the scripts being used, which were written for a previous version of s3ql, need improving, I have started reading the documenation to check, also there is a backup script which has some features the one above doesn't.
comment:8 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 1.18
- Total Hours changed from 5.3 to 6.48
Looking at the Crin2 firewall stats I think we have the situation where after unmounting "the file system may continue to upload data in the background for a while longer", and that might also explain why df -h is taking ages to list the file systems mounted on the server.
The backup scripts did have one error in them regarding which unmount script was called, so this has been fixed, this is the web2 script:
#!/bin/bash
# Check that these 4 vairables are correct:
# The bucket name
BUCKET="crin-gq-web2"
# The directories we want to backup, space seperated
BACKUP_DIRS="/media/web2.crin.org/root /media/web2.crin.org/home /media/web2.crin.org/etc /media/web2.crin.org/var/www /media/web2.crin.org/var/backups"
# The s3ql mount script
MNT_CMD="mnt-s3ql-web2"
# The s3ql unmount script
UMNT_CMD="umnt-sftp-web2"
# mount directory
MOUNT="/media"
# base directory for backups
BACKUP_ROOT="${MOUNT}/${BUCKET}"
# the latest backup
BACKUP_LATEST="${BACKUP_ROOT}/latest"
DATE=$(date "+%Y-%m-%d_%H-%M")
YEAR=$(date "+%Y")
MONTH=$(date "+%m")
# archive of the latest backup
BACKUP_ARCHIVE="${BACKUP_ROOT}/${YEAR}/${MONTH}/$DATE"
# rsync command
#RSYNC="rsync -av --delete --timeout=120 --bwlimit=10000"
RSYNC="rsync -aq --delete --timeout=120 --bwlimit=10000"
# check that the script is being run by root
if [[ "$(id -u)" != "0" ]] ; then
echo "You must run $0 as root or via sudo"
exit 2
fi
# check that the s3ql file system is mounted
MOUNTED=$(df -h | grep ${BUCKET})
if [[ ! ${MOUNTED} ]]; then
echo "${BACKUP_ROOT} is not mounted"
# unmount s3ql filesystem with check to see of force is needed here
FORCE_UNMOUNT=$($UMNT_CMD 2>&1 | grep "Can not check mounted file system.")
# force is needed to unmount the s3ql file system
if [[ ${FORCE_UNMOUNT} ]]; then
echo "using force to unmount ${BACKUP_ROOT}"
$UMNT_CMD --force
fi
# mount the s3ql filesystem
echo "Mounting ${BACKUP_ROOT}"
$MNT_CMD
fi
# copy data to $BACKUP_LATEST
for d in ${BACKUP_DIRS}; do
# check the s3ql file system is still mounted
MOUNTED=$(df -h | grep ${BUCKET})
if [[ ${MOUNTED} ]]; then
echo "Starting backup of ${d}"
test -d ${BACKUP_LATEST}${d} || mkdir -p ${BACKUP_LATEST}${d} || exit 1
${RSYNC} ${d}/ ${BACKUP_LATEST}${d}/ || exit 1
echo "Completed backup of ${d}"
else
echo "${BACKUP_ROOT} is not mounted"
exit 1
fi
done
# copy $BACKUP_LATEST to $BACKUP_ARCHIVE and make it immutable
# make the parent directory for todays backup
test -d ${BACKUP_ROOT}/${YEAR}/${MONTH} || mkdir -p ${BACKUP_ROOT}/${YEAR}/${MONTH} || exit 1
# copy the latest backup to a directory based on the date
echo "Copying $BACKUP_LATEST to $BACKUP_ARCHIVE"
s3qlcp $BACKUP_LATEST $BACKUP_ARCHIVE || exit 1
# make the date based backup immutable
echo "Making $BACKUP_ARCHIVE immutable"
s3qllock $BACKUP_ARCHIVE || exit 1
echo "$0 Completed successfully"
exit 0
The s3ql_backup.sh script does differ in some ways, the directory names are designed to work with the expire_backups.py script, so that is a good reason to consider switching to use this, also the rsync command differs, we have:
RSYNC="rsync -aq --delete --timeout=120 --bwlimit=10000"
And s3ql_backup.sh has:
rsync -aHAXx --delete-during --delete-excluded --partial -v \
--exclude /.cache/ \
--exclude /.s3ql/ \
--exclude /.thumbnails/ \
--exclude /tmp/ \
"/home/my_username/" "./$new_backup/"
However the problems not appear to be related to the rsync command.
Trying the unmount and check the crin-gq-wiki bucket:
umnt-s3ql-wiki --force
fusermount: failed to unmount /media/crin-gq-wiki: Invalid argument
mount.s3ql: no process found
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-wiki
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 500 objects so far..Encountered ConnectionTimedOut exception (send/recv timeout exceeded), retrying call to RetryIterator.__next__ for the 3-th time...
..processed 3500 objects so far..
Checking objects (sizes)...
Object 2869 has no size information, retrieving from backend...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.11.1', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1213, in main
dump_metadata(db, fh)
File "/usr/lib/s3ql/s3ql/metadata.py", line 149, in dump_metadata
dump_table(table, order, columns, db=db, fh=fh)
File "s3ql/deltadump.pyx", line 317, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:4314)
File "s3ql/deltadump.pyx", line 364, in s3ql.deltadump.dump_table (src/s3ql/deltadump.c:3963)
ValueError: Can't dump NULL values
The above looks, very much like this error which was fixed on 2014-11-09 and looking at the releases that means it was fixed in s3ql-2.12 but we are running:
fsck.s3ql --version S3QL 2.11.1
Debian testing and unstable have 2.13+dfsg-1, so lets try that on Crin1, create /etc/apt/preferences containing;
Package: * Pin: release n=jessie Pin-Priority: 900 Package: s3ql Pin: release n=stretch Pin-Priority: 910
And add the following to /etc/apt/sources.list:
# stretch deb http://speglar.simnet.is/debian/ stretch main deb-src http://speglar.simnet.is/debian/ stretch main
Update and see what is on offer:
apt-get update
apt-cache policy s3ql
s3ql:
Installed: 2.11.1+dfsg-2
Candidate: 2.13+dfsg-1
Package pin: 2.13+dfsg-1
Version table:
2.13+dfsg-1 910
500 http://speglar.simnet.is/debian/ stretch/main amd64 Packages
*** 2.11.1+dfsg-2 910
900 http://speglar.simnet.is/debian/ jessie/main amd64 Packages
100 /var/lib/dpkg/status
Install the stretch version and try the filesystem check again:
apt-get install s3ql
umnumnt-s3ql-wiki --force
fusermount: failed to unmount /media/crin-gq-wiki: Invalid argument
mount.s3ql: no process found
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 449, in _build_master
ws.require(__requires__)
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 745, in require
needed = self.resolve(parse_requirements(requirements))
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 644, in resolve
raise VersionConflict(dist, req)
pkg_resources.VersionConflict: (dugong 3.3 (/usr/lib/python3/dist-packages), Requirement.parse('dugong>=3.4'))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 5, in <module>
from pkg_resources import load_entry_point
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 2876, in <module>
working_set = WorkingSet._build_master()
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 451, in _build_master
return cls._build_from_requirements(__requires__)
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 464, in _build_from_requirements
dists = ws.resolve(reqs, Environment())
File "/usr/lib/python3/dist-packages/pkg_resources.py", line 639, in resolve
raise DistributionNotFound(req)
pkg_resources.DistributionNotFound: dugong>=3.4
So that don't work, switching back to the jessie version:
rm /etc/apt/preferences vi /etc/apt/sources.list aptitude remove s3ql aptitude update aptitude install s3ql
It looks like we might have to install s3ql from source to get a fixed version.
Changed 3 years ago by chris
comment:9 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 6.48 to 6.63
Regarding the issue with the s3ql version found in ticket:11#comment:8, where we hit a bug that is only solved in the s3ql version in Debian 9 (stretch) and not the version in Debian 8 (Jessie), which we are running.
I really don't want to start compiling source code on the servers if it can be avoided (it makes things harder to maintain in the long run, it could result in python3 having to be compiled from source, it might end up taking up a lot of time and we are already over the estimate of 6 hours for this ticket), also the memory usage of mount.s3ql is significant:
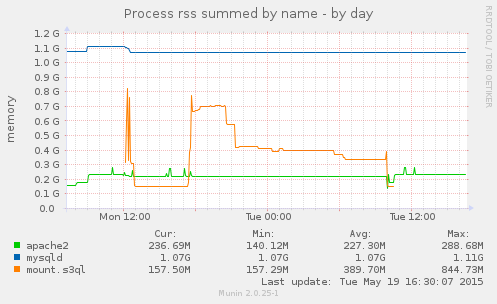
Jonas -- could we have a small (512MB RAM) virtual server running Debian stretch (unstable) just for doing the s3 backups? If we had machine just for this it could mount the file systems to be backed up via sshfs and also the s3 space via s3ql and it would mean that the database server and web servers wouldn't need to allocate between 150MB and 850MB of RAM for the backup processes.
comment:10 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 6.63 to 6.78
Checking where things are with the backups on Crin2:
df -h
df: ‘/media/crin-gq-web1’: Transport endpoint is not connected
Filesystem Size Used Avail Use% Mounted on
/dev/dm-0 121G 22G 94G 19% /
udev 10M 0 10M 0% /dev
tmpfs 793M 33M 761M 5% /run
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 236M 33M 191M 15% /boot
web1:/ 9.4G 1.5G 7.4G 17% /media/web1.crin.org
umnt-s3ql-web1
File system appears to have crashed.
Can not check mounted file system.
umnt-s3ql-web1 --force
mount.s3ql: no process found
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-web1
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 32500 objects so far..Deleted spurious object 4774
Deleted spurious object 8748
Deleted spurious object 9265
Deleted spurious object 15484
Deleted spurious object 32211
Checking objects (sizes)...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
..inodes..
..inode_blocks..
..symlink_targets..
..names..
..contents..
..ext_attributes..
Compressing and uploading metadata...
Wrote 1 MiB of compressed metadata.
Cycling metadata backups...
Backing up old metadata...
Unexpected server reply: expected XML, got:
200 OK
Content-Length: 0
x-amz-meta-data-03: XXX
x-amz-meta-data-02: XXX
x-amz-meta-data-01: XXX
x-amz-meta-data-00: XXX
x-amz-id-2: XXX
x-amz-meta-md5: XXX
Last-Modified: Wed, 20 May 2015 09:37:23 GMT
ETag: "XXX"
x-amz-request-id: XXX
x-amz-meta-format: pickle
Content-Type: text/html; charset="UTF-8"
X-Trans-Id: XXX
Date: Wed, 20 May 2015 09:37:23 +0000
Connection: keep-alive
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.11.1', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1224, in main
cycle_metadata(backend)
File "/usr/lib/s3ql/s3ql/metadata.py", line 127, in cycle_metadata
backend.copy("s3ql_metadata", "s3ql_metadata_bak_0")
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 290, in copy
self._copy_or_rename(src, dest, rename=False, metadata=metadata)
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 323, in _copy_or_rename
self.backend.copy(src, dest, metadata=meta_raw)
File "/usr/lib/s3ql/s3ql/backends/common.py", line 46, in wrapped
return method(*a, **kw)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 376, in copy
root = self._parse_xml_response(resp, body)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 528, in _parse_xml_response
raise RuntimeError('Unexpected server response')
RuntimeError: Unexpected server response
So trying again:
umnt-s3ql-web1 --force
fusermount: failed to unmount /media/crin-gq-web1: Invalid argument
mount.s3ql: no process found
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-web1
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 32500 objects so far..
Checking objects (sizes)...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
..inodes..
..inode_blocks..
..symlink_targets..
..names..
..contents..
..ext_attributes..
Compressing and uploading metadata...
Wrote 1 MiB of compressed metadata.
Cycling metadata backups...
Backing up old metadata...
Unexpected server reply: expected XML, got:
200 OK
Content-Length: 0
x-amz-meta-data-03: XXX
x-amz-meta-data-02: XXX
x-amz-meta-data-01: XXX
x-amz-meta-data-00: XXX
x-amz-id-2: XXX
x-amz-meta-md5: XXX
Last-Modified: Wed, 20 May 2015 09:41:40 GMT
ETag: "XXX"
x-amz-request-id: XXX
x-amz-meta-format: pickle
Content-Type: text/html; charset="UTF-8"
X-Trans-Id: XXX
Date: Wed, 20 May 2015 09:41:40 +0000
Connection: keep-alive
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.11.1', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1224, in main
cycle_metadata(backend)
File "/usr/lib/s3ql/s3ql/metadata.py", line 121, in cycle_metadata
cycle_fn("s3ql_metadata_bak_%d" % i, "s3ql_metadata_bak_%d" % (i + 1))
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 290, in copy
self._copy_or_rename(src, dest, rename=False, metadata=metadata)
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 323, in _copy_or_rename
self.backend.copy(src, dest, metadata=meta_raw)
File "/usr/lib/s3ql/s3ql/backends/common.py", line 46, in wrapped
return method(*a, **kw)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 376, in copy
root = self._parse_xml_response(resp, body)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 528, in _parse_xml_response
raise RuntimeError('Unexpected server response')
RuntimeError: Unexpected server response
comment:11 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.5
- Total Hours changed from 6.78 to 7.28
Setting up the new Crin3 backup server.
Add user account and ssh keys
export NEWUSER="chris" adduser $NEWUSER adduser $NEWUSER sudo mkdir /home/$NEWUSER/.ssh touch /home/$NEWUSER/.ssh/authorized_keys chmod 600 /home/$NEWUSER/.ssh/authorized_keys chmod 700 /home/$NEWUSER/.ssh chown -R $NEWUSER:$NEWUSER /home/$NEWUSER/.ssh vim /home/$NEWUSER/.ssh/authorized_keys
Install some essential tools:
apt-get install rsync vim screen sshfs fail2ban iptables-persistent logwatch metche
Sort out the editor:
update-alternatives --config editor echo "syntax on" > ~/.vimrc
Lock down ssh, edit these lines in /etc/ssh/sshd_config:
#PermitRootLogin yes PermitRootLogin no AllowGroups sudo PasswordAuthentication no
Restart ssh.
Install a couple of script, for doing updates and recording them:
cd /usr/local/bin wget https://svn.webarch.net/scripts/usr/local/bin/a-up --no-check-certificate -O a-up; chmod 755 a-up wget https://svn.webarch.net/scripts/usr/local/bin/logchange --no-check-certificate -O logchange; chmod 755 logchange
Sort out the name of the server, add a DNS entry.
vi /etc/hosts /etc/hostname /etc/mailname
Sort out where root email goes:
vim /etc/aliases newaliases
Switch the server to Debian Stretch from Debian Jessie, edit /etc/sources:
# deb http://speglar.simnet.is/debian/ stretch main deb http://speglar.simnet.is/debian/ stretch main non-free contrib deb-src http://speglar.simnet.is/debian/ stretch main non-free contrib deb http://security.debian.org/ stretch/updates main contrib non-free deb-src http://security.debian.org/ stretch/updates main contrib non-free # stretch-updates, previously known as 'volatile' deb http://speglar.simnet.is/debian/ stretch-updates main contrib non-free deb-src http://speglar.simnet.is/debian/ stretch-updates main contrib non-free
Then:
screen apt-get update
This will take a while, I'll come back to this later...
comment:12 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 1.5
- Total Hours changed from 7.28 to 8.78
Continuing the upgrade:
apt-get dist-upgrade reboot
Install some more packages:
aptitude install sudo s3ql
Set up ssh so the server can mount the GreenQloud servers:
ssh-keygen -t rsa -b 2048
Add the public key to the GreenQloud servers, prefixed with the crin3.crin.org IP address:
from="93.95.228.198" ssh-rsa AAA...
Create a /root/.ssh/config file with all the servers in it, create mount points for the servers:
mkdir /media/db1.crin.org mkdir /media/web1.crin.org mkdir /media/web2.crin.org mkdir /media/wiki.crin.org
Mount the live database server:
sshfs db1:/ /media/db1.crin.org/ root@crin3:~# df -h Filesystem Size Used Avail Use% Mounted on /dev/dm-0 15G 1.2G 13G 9% / udev 10M 0 10M 0% /dev tmpfs 99M 4.4M 95M 5% /run tmpfs 248M 0 248M 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 248M 0 248M 0% /sys/fs/cgroup /dev/sda1 236M 33M 191M 15% /boot db1:/ 9.4G 2.3G 6.6G 26% /media/db1.crin.org
Change the sshd_config on Crin1 and restart ssh
#PermitRootLogin no PermitRootLogin without-password
So that the /root/.s3ql directory can copied:
mkdir .s3ql chmod 700 .s3ql/ rsync -av crin1:.s3ql/ .s3ql/ rm .s3ql/*log*
Try mounting the s3ql space:
mkdir /media/crin-gq-db1 chmod 700 /media/crin-gq-db1 mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.db1 --allow-root s3c://s.qstack.advania.com:443/crin-gq-db1 /media/crin-gq-db1 Using 2 upload threads (memory limited). Autodetected 65498 file descriptors available for cache entries Backend reports that fs is still mounted elsewhere, aborting.
So check it is not mounted elsewhere, on Crin1:
umount.s3ql /media/crin-gq-db1 /media/crin-gq-db1 is not on an S3QL file system
Based on the FAQ it should be safe to run fsck, so copy all the scripts over:
cd /usr/local/bin rsync -av crin1:/usr/local/bin/backup* . rsync -av crin1:/usr/local/bin/mnt* . rsync -av crin1:/usr/local/bin/umnt* . rsync -av crin2:/usr/local/bin/backup* . rsync -av crin2:/usr/local/bin/mnt* . rsync -av crin2:/usr/local/bin/umnt* . scp crin2:/root/.s3ql/authinfo2.web1 /root/.s3ql/
Filesystem check:
umnt-s3ql-db1
/media/crin-gq-db1 is not on an S3QL file system
Starting fsck of s3c://s.qstack.advania.com:443/crin-gq-db1/
File system revision too old, please run `s3qladm upgrade` first.
s3qladm --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.db1 upgrade s3c://s.qstack.advania.com:443/crin-gq-db1
Getting file system parameters..
Backend reports that fs is still mounted. If this is not the case, the
file system may have not been unmounted cleanly or the data from the
most-recent mount may have not yet propagated through the backend. In
the later case, waiting for a while should fix the problem, in the
former case you should try to run fsck on the computer where the file
system has been mounted most recently.
The last S3QL version that supported this file system revision
was 2.12. To run this version's fsck.s3ql, proceed along
the following steps:
$ wget http://s3ql.googlecode.com/files/s3ql-2.12.tar.bz2 || wget https://bitbucket.org/nikratio/s3ql/downloads/s3ql-2.12.tar.bz2
$ tar xjf s3ql-2.12.tar.bz2
$ (cd s3ql-2.12; ./setup.py build_ext)
$ s3ql-2.12/bin/fsck.s3ql <options>
So, we are stuck, we get an error doing a fsck with the old s3ql and the new s3ql wants us to run the old version, so I think the way forward is to delete the bucket and start again.
However there isn't a delete bucket option I can find at https://qstack.advania.com/storage so a new one was created called crin-greenqloud-db1 and ~/.s3ql/authinfo2.greenqloud.db1 was created and a filesystem was created:
mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2.greenqloud.db1 s3c://s.qstack.advania.com:443/crin-greenqloud-db1 Before using S3QL, make sure to read the user's guide, especially the 'Important Rules to Avoid Loosing Data' section. Enter encryption password: Confirm encryption password: Generating random encryption key... Creating metadata tables... Dumping metadata... ..objects.. ..blocks.. ..inodes.. ..inode_blocks.. ..symlink_targets.. ..names.. ..contents.. ..ext_attributes.. Compressing and uploading metadata... Wrote 151 bytes of compressed metadata. Please store the following master key in a safe location. It allows decryption of the S3QL file system in case the storage objects holding this information get corrupted: ---BEGIN MASTER KEY--- XXX ---END MASTER KEY---
The encryption password was saved to /root/.s3ql/authinfo2.greenqloud.db1, the mounting and unmounting scripts were edited and the filesystem was mounted:
mkdir /media/crin-greenqloud-db1 chmod 700 /media/crin-greenqloud-db1 mnt-s3ql-db1
And the backup was started:
screen backup-s3ql-db1
This will take a while to run... I'll check back on it later.
If it goes OK then TODO:
- Create new buckets for the other servers
- Edit the backups scripts for the new buckets
- Run all the backups
- Cron all the backups
- Ask Advania to delete the unneeded buckets
- Setup munin-node
- Setup iptables-persistent
- Document the backup setup
comment:13 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.25
- Total Hours changed from 8.78 to 9.03
That backup failed:
rsync: write failed on "/media/crin-greenqloud-db1/latest/media/db1.crin.org/var/backups/mysql/databases/crin/field_data_body.sql": Transport endpoint is not connected (107) rsync error: error in file IO (code 11) at receiver.c(393) [receiver=3.1.1]
Trying to recover and re-run:
umnt-s3ql-db1
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/umount.s3ql", line 9, in <module>
load_entry_point('s3ql==2.13', 'console_scripts', 'umount.s3ql')()
File "/usr/lib/s3ql/s3ql/umount.py", line 178, in main
assert_s3ql_mountpoint(options.mountpoint)
File "/usr/lib/s3ql/s3ql/common.py", line 279, in assert_s3ql_mountpoint
ctrlfile = assert_s3ql_fs(mountpoint)
File "/usr/lib/s3ql/s3ql/common.py", line 244, in assert_s3ql_fs
if not (CTRL_NAME not in llfuse.listdir(path)
File "fuse_api.pxi", line 42, in llfuse.capi.listdir (src/llfuse/capi_linux.c:19758)
OSError: [Errno 107] Transport endpoint is not connected: '/media/crin-greenqloud-db1'
Can not check mounted file system.
umnt-s3ql-db1 --force
mount.s3ql: no process found
Starting fsck of s3c://s.qstack.advania.com:443/crin-greenqloud-db1/
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Committing block 0 of inode 77 to backend
...
Unexpected server reply: expected XML, got:
200 OK
x-amz-meta-006: 'format_version': 2,
x-amz-meta-007: 'compression': 'None',
Content-Length: 0
x-amz-meta-005: 'encryption': 'AES_v2',
x-amz-meta-002: 'data': XXX
x-amz-meta-003: XXX
x-amz-meta-000: 'object_id': 's3ql_metadata_bak_1',
x-amz-meta-001: 'nonce': XXX
x-amz-id-2: XXX
x-amz-meta-md5: XXX
x-amz-meta-004: 'signature': XXX
Last-Modified: Tue, 02 Jun 2015 13:27:06 GMT
ETag: "XXX"
x-amz-request-id: XXX
x-amz-meta-format: raw2
Content-Type: text/html; charset="UTF-8"
X-Trans-Id: XXX
Date: Tue, 02 Jun 2015 13:27:06 +0000
Connection: keep-alive
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.13', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1307, in main
cycle_metadata(backend)
File "/usr/lib/s3ql/s3ql/metadata.py", line 121, in cycle_metadata
cycle_fn("s3ql_metadata_bak_%d" % i, "s3ql_metadata_bak_%d" % (i + 1))
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 291, in copy
self._copy_or_rename(src, dest, rename=False, metadata=metadata)
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 325, in _copy_or_rename
self.backend.copy(src, dest, metadata=meta_raw)
File "/usr/lib/s3ql/s3ql/backends/common.py", line 52, in wrapped
return method(*a, **kw)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 404, in copy
root = self._parse_xml_response(resp, body)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 554, in _parse_xml_response
raise RuntimeError('Unexpected server response')
RuntimeError: Unexpected server response
So I'm afraid using the Debian Stretch version of s3ql hasn't fixed the problem.
If you want me to continue to try to get s3ql storage working with advania.com then I'll have to raise a issue both with the developer of s3ql and also with advania and I have no idea how long this might take to resolve.
If you need a quick alternative then I can suggest the Webarchitects backup space -- this could be setup quickly, I don't think s3ql backups using advania can be.
comment:14 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.3
- Total Hours changed from 9.03 to 9.33
Some questions from Jonas:
Could we have not anticipated that before choosing Advania for backups?
I don't think so, the Advania software stack has been built by GreenQloud and they support s3ql. With hindsight we could have asked some of the durability and consistency questions, but I'm not sure that the problem is related to these matters.
If s3ql storage is currently not supported by Advania, it seems that we made a bad decision.
We were not to know that these problems would arise, the Advania site hosts a s3ql how to that I originally wrote for GreenQloud (you have to login to access it, but the login doesn't appear to be working right now so I can't get the URL of the article) -- I'm sure they would appreciate feedback regarding the problems we have been having and would be happy to work with us to help resolve the problem. The same goes for the s3ql developer and I'd be very happy to work on resolving this problem the only problem with trying to fix it is that it will take some time to resolve and I don't know how much time.
Is this putting us back into the issue of having to choose a different place or can we have a different *kind *of backup running at Advania?
Yes that is a possibility, but no other S3 storage system supports the key things that s3ql offers:
comment:15 Changed 3 years ago by chris
The plan is to use the GreenCloud servers as backup servers for the time being, I'll try to sort this out over the weekend or early next week. Crin1 is now live for ownCloud, https://cloud.crin.org/ and Piwik, https://stats.crin.org/
comment:17 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.65
- Total Hours changed from 9.33 to 9.98
Setting up the GreenQloud crin-web1 server up to host backups:
sudo -i mkdir /var/backups/1984 mkdir /var/backups/1984/crin1 mkdir /var/backups/1984/crin2 mkdir /var/backups/1984/crin3 chmod 700 /var/backups/1984
The /etc/ssh/sshd_config file was edited:
#PermitRootLogin yes PermitRootLogin without-password
And the public ssh keys from Crin1, Crin2 and Crin3 were added to /root/.ssh/authorized_keys prefixed with the server IP addresses, eg:
from="93.95.228.179" ssh-rsa AAAA...
On the crin-db1 server the MySQL database are dumped with a file per directory as there were problems uploading very big SQL files using s3ql, so this script, was copied to Crin1 and it has been posted to wiki:DumpMysqlTables, it was copied to the server as /usr/local/bin/backup-mysql and run, and the backup directory was set to only be readable by root (the script should really sort this out):
chmod 700 /var/backups/mysql/databases/
It was set to run at 1am every morning:
# m h dom mon dow command 01 01 * * * /usr/local/bin/backup-mysql
And /usr/local/bin/rsync-backup was created containing:
#!/bin/bash RSYNC="rsync -av" DEST="web1:/var/backups/1984/crin1" $RSYNC /var/backups/mysql/databases/ $DEST/var/backups/mysql/databases/ $RSYNC /etc/ $DEST/etc/ $RSYNC /var/www/ $DEST/www/
The directories were created on crin-web1:
mkdir -p /var/backups/1984/crin1/var/backups/mysql/databases mkdir /var/backups/1984/crin1/etc mkdir /var/backups/1984/crin1/www
And then it was run in screen:
screen /usr/local/bin/rsync-backup
I'll check back later to see it it completed OK. If it wall went well then the same things will need to be set up for Crin2 and Crin3.
comment:18 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 9.98 to 10.13
The back seems to have run OK, so it has been added to the Crin1 root crontab:
30 01 * * * /usr/local/bin/rsync-backup
And the script was copied to Crin2 and edited:
#!/bin/bash RSYNC="rsync -av" DEST="web1:/var/backups/1984/crin2" $RSYNC /etc/ $DEST/etc/ $RSYNC /var/www/ $DEST/www/
The destination directories were created on crin-web1 and the backup script was run in screen.
comment:19 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.1
- Total Hours changed from 10.13 to 10.23
We have run out of space in /var/ on the GreenQloud server, so changing it so that /var/www on Crin2 is backed up to /var/www on crin-web1:
mkdir /var/backups/1984/crin2/var cd /var/backups/1984/crin2/var ln -s /var/www
And the script on Crin2 was changed:
#!/bin/bash RSYNC="rsync -av" DEST="web1:/var/backups/1984/crin2" $RSYNC /etc/ $DEST/etc/ $RSYNC /var/www/ $DEST/var/www/
This means that the backups will overwrite the old files, which is fine unless something goes horribly wrong after switching to 1984.is and we need to switch back to GreenCloud... So the settings.php file on crin-web1 was backed up:
cp /var/www/crin/sites/default/settings.php /root/
comment:21 Changed 3 years ago by gillian
Hi Jenny,
A few hiccups with backup on GreenQloud but all ok now from my
understanding?
Thanks
On Friday, 12 June 2015, CRIN Trac <trac@trac.crin.org> wrote:
> #11: Set up backups
> -------------------------------------+-------------------------------------
> Reporter: chris | Owner: chris
> Type: defect | Status: new
> Priority: major | Milestone: Install and
> | configure crin1
> Component: backups | Version:
> Resolution: | Keywords:
> Estimated Number of Hours: 6 | Add Hours to Ticket: 0.1
> Billable?: 1 | Total Hours: 10.13
> -------------------------------------+-------------------------------------
> Changes (by chris):
>
> * hours: 0 => 0.1
> * totalhours: 10.13 => 10.23
>
>
> Comment:
>
> We have run out of space in `/var/` on the !GreenQloud server, so changing
> it so that `/var/www` on [[Crin2]] is backed up to `/var/www` on `crin-
> web1`:
>
> {{{
> mkdir /var/backups/1984/crin2/var
> cd /var/backups/1984/crin2/var
> ln -s /var/www
> }}}
>
> And the script on [[Crin2]] was changed:
>
> {{{
> #!/bin/bash
>
> RSYNC="rsync -av"
> DEST="web1:/var/backups/1984/crin2"
>
> $RSYNC /etc/ $DEST/etc/
> $RSYNC /var/www/ $DEST/var/www/
> }}}
>
> This means that the backups will overwrite the old files, which is fine
> unless something goes horribly wrong after switching to 1984.is and we
> need to switch back to !GreenCloud... So the `settings.php` file on `crin-
> web1` was backed up:
>
> {{{
> cp /var/www/crin/sites/default/settings.php /root/
> }}}
>
> --
> Ticket URL: <https://trac.crin.org.archived.website/trac/ticket/11#comment:19>
> CRIN Trac <https://trac.crin.org.archived.website/trac>
> Trac project for CRIN website and servers.
>
--
Gillian Harrow
Organisational Development Manager
*Child Rights International Network - CRIN*
Unit W125-127, Westminster Business Square
1-45 Durham Street
London SE11 5JH
United Kingdom
E: gillian@crin.org
T: +44 (0)20 7401 2257
Website: www.crin.org
Twitter: @CRINwire
comment:22 follow-up: ↓ 23 Changed 3 years ago by gillian
Hi Chris,
I often find these tickets a bit confusing.
Please can you send Jenny and I an update on what the billable hours are
for the back up to Green Qloud.
I am looking at:
Billable?: 1 | Total Hours: 10.13
Many thanks,
Gillian
On 12 June 2015 at 10:44, CRIN Trac <trac@trac.crin.org> wrote:
> #11: Set up backups
> -------------------------------------+-------------------------------------
> Reporter: chris | Owner: chris
> Type: defect | Status: new
> Priority: major | Milestone: Install and
> | configure crin1
> Component: backups | Version:
> Resolution: | Keywords:
> Estimated Number of Hours: 6 | Add Hours to Ticket: 0.1
> Billable?: 1 | Total Hours: 10.13
> -------------------------------------+-------------------------------------
> Changes (by chris):
>
> * hours: 0 => 0.1
> * totalhours: 10.13 => 10.23
>
>
> Comment:
>
> We have run out of space in `/var/` on the !GreenQloud server, so changing
> it so that `/var/www` on [[Crin2]] is backed up to `/var/www` on `crin-
> web1`:
>
> {{{
> mkdir /var/backups/1984/crin2/var
> cd /var/backups/1984/crin2/var
> ln -s /var/www
> }}}
>
> And the script on [[Crin2]] was changed:
>
> {{{
> #!/bin/bash
>
> RSYNC="rsync -av"
> DEST="web1:/var/backups/1984/crin2"
>
> $RSYNC /etc/ $DEST/etc/
> $RSYNC /var/www/ $DEST/var/www/
> }}}
>
> This means that the backups will overwrite the old files, which is fine
> unless something goes horribly wrong after switching to 1984.is and we
> need to switch back to !GreenCloud... So the `settings.php` file on `crin-
> web1` was backed up:
>
> {{{
> cp /var/www/crin/sites/default/settings.php /root/
> }}}
>
> --
> Ticket URL: <https://trac.crin.org.archived.website/trac/ticket/11#comment:19>
> CRIN Trac <https://trac.crin.org.archived.website/trac>
> Trac project for CRIN website and servers.
>
--
Gillian Harrow
Organisational Development Manager
*Child Rights International Network - CRIN*
Unit W125-127, Westminster Business Square
1-45 Durham Street
London SE11 5JH
United Kingdom
E: gillian@crin.org
T: +44 (0)20 7401 2257
Website: www.crin.org
Twitter: @CRINwire
comment:23 in reply to: ↑ 22 Changed 3 years ago by chris
Replying to gillian:
I often find these tickets a bit confusing.
Sorry about that.
Please can you send Jenny and I an update on what the billable hours are
for the back up to Green Qloud.
I am looking at:
Billable?: 1 | Total Hours: 10.13
That is the total time for the ticket.
Before I set up the backups to go to the GreenQloud server a total of 9h 19m of time had been recorded on this ticket, so approx 1 hour has been spent since, see the total hours here:
https://trac.crin.org.archived.website/trac/ticket/11#comment:17
I hope that is clear.
comment:24 Changed 3 years ago by gillian
Yes, it is clear. Thank you. On 12 June 2015 at 14:57, CRIN Trac <trac@trac.crin.org> wrote: > #11: Set up backups > -------------------------------------+------------------------------------- > Reporter: chris | Owner: chris > Type: defect | Status: new > Priority: major | Milestone: Install and > | configure crin1 > Component: backups | Version: > Resolution: | Keywords: > Estimated Number of Hours: 6 | Add Hours to Ticket: 0 > Billable?: 1 | Total Hours: 10.23 > -------------------------------------+------------------------------------- > > Comment (by chris): > > Replying to [comment:22 gillian]: > > > > I often find these tickets a bit confusing. > > Sorry about that. > > > Please can you send Jenny and I an update on what the billable hours are > > for the back up to Green Qloud. > > I am looking at: > > Billable?: 1 | Total Hours: 10.13 > > That is the total time for the ticket. > > Before I set up the backups to go to the !GreenQloud server a total of 9h > 19m of time had been recorded on this ticket, so approx 1 hour has been > spent since, see the total hours here: > > https://trac.crin.org.archived.website/trac/ticket/11#comment:17 > > I hope that is clear. > > -- > Ticket URL: <https://trac.crin.org.archived.website/trac/ticket/11#comment:23> > CRIN Trac <https://trac.crin.org.archived.website/trac> > Trac project for CRIN website and servers. > -- Gillian Harrow Organisational Development Manager *Child Rights International Network - CRIN* Unit W125-127, Westminster Business Square 1-45 Durham Street London SE11 5JH United Kingdom E: gillian@crin.org T: +44 (0)20 7401 2257 Website: www.crin.org Twitter: @CRINwire
comment:25 Changed 3 years ago by chris
Jenny / Gillian : is it OK if I spend up to 30 mins on this ticket checking that the backups are all working and shutting down the servers we no longer need at GreenQloud?
comment:26 Changed 3 years ago by gillian
Hi Chris, Jenny I haven't tested Piwik or OwnCloud and will not have an opportunity to do that until after 9pm tonight. Jenny, have you time to look in and then I will tonight? Apologies, Gillian On 30 June 2015 at 11:16, CRIN Trac <trac@trac.crin.org> wrote: > #11: Set up backups > -------------------------------------+------------------------------------- > Reporter: chris | Owner: chris > Type: defect | Status: new > Priority: major | Milestone: Install and > | configure crin1 > Component: backups | Version: > Resolution: | Keywords: > Estimated Number of Hours: 6 | Add Hours to Ticket: 0 > Billable?: 1 | Total Hours: 10.23 > -------------------------------------+------------------------------------- > > Comment (by chris): > > Jenny / Gillian : is it OK if I spend up to 30 mins on this ticket > checking that the backups are all working and shutting down the servers we > no longer need at GreenQloud? > > -- > Ticket URL: <https://trac.crin.org.archived.website/trac/ticket/11#comment:25> > CRIN Trac <https://trac.crin.org.archived.website/trac> > Trac project for CRIN website and servers. > -- Gillian Harrow Organisational Development Manager *Child Rights International Network - CRIN* Unit W125-127, Westminster Business Square 1-45 Durham Street London SE11 5JH United Kingdom E: gillian@crin.org T: +44 (0)20 7401 2257 Website: www.crin.org Twitter: @CRINwire
comment:27 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.25
- Resolution set to wontfix
- Status changed from new to closed
- Total Hours changed from 10.23 to 10.48
Closing this ticket as won't fix, email from Gillian:
1984 makes backups of our data
So on Crin1 this cron job was commented out:
#30 01 * * * /usr/local/bin/rsync-backup
The following one which dumps a copy of the MySQL database into plain text files was kept as this will ensure that 1984 backups contain restorable copies of the databases.
01 01 * * * /usr/local/bin/backup-mysql
The Crin3 server can be also be shutdown.
comment:28 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.5
- Resolution wontfix deleted
- Status changed from closed to reopened
- Total Hours changed from 10.48 to 10.98
I have re-opened this ticket, regarding how much data there is to backup:
Crin1
196K ./usr/local 7.1M ./etc 695M ./home 1.5G ./root 1.5G ./var/backups 672M ./var/www 5G TOTAL
Crin2
6.2M ./root 7.2M ./etc 268K ./home 20G ./var/www 8.4M ./var/backups 13M ./usr/local 21G TOTAL
Crin 4
184K ./home 6.8M ./etc 2.1M ./root 31M ./var/www 14M ./usr/local 100M TOTAL
We could use rdiff-backup via backupninja to another virtual server. A 4 unit VPS with 32G of space would be the minimum needed, but wouldn't give much space to grow, a 6 unit VPS with 48G of space might make more sense (£47.94 per month) the CRIN3 server would also not be needed with this approach, so could be replaced by a backup server.
The reason I have advised against a solution like this in the past is cost -- it is far more expensive per G of space compared with, for example Advania OpenCloud - Storage, which is from 0,11$ per G per month, so 48G of space there would be about £3.40 per month:
comment:29 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.5
- Total Hours changed from 10.98 to 11.48
I have just sent the following email to info@…:
Date: Wed, 22 Jul 2015 16:48:37 +0100 From: Chris Croome <chris@webarchitects.co.uk> To: info@advania.com Subject: Problem with Advania OpenCloud Storage and S3QL Hi I have been trying to set up a backup solution for CRIN (https://www.crin.org/) using S3QL and your S3 OpenCloud Storage but have this error: - https://trac.crin.org.archived.website/trac/ticket/11#comment:13 I don't know if this is an issue with S3QL or your servers, I'll also raise it with the S3QL developer. Do you have any advice? I'd be happy to work with you to resolve this issue. All the best Chris
I have also opened a ticket at the S3QL project site:
Problem with Advania S3 storage space
I have been trying to use the Debian S3QL package to backup data to Advania S3 storage space, http://www.advania.com/datacentres/solutions/advania-cloud-services/ and using Debian 8, Jessie, I came across this issue:
https://trac.crin.org.archived.website/trac/ticket/11#comment:8
Which was solved here:
https://bitbucket.org/nikratio/s3ql/commits/dd846bab60fc
So I switched to using the Debian unstable version of S3QL and that solved this issue but I then had another problem:
https://trac.crin.org.archived.website/trac/ticket/11#comment:13
I don't know if this is a Advania or a S3QL issue, I have emailed them to ask. Do you have any suggestions how I might get this working?
comment:30 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 2.45
- Total Hours changed from 11.48 to 13.93
Starting from the beginning again...
The servers that need backing up are Crin1, Crin2 and Crin4, and the server we are going to use to do the backups is Crin3. So on Crin3 the other 3 server files systems were mounted (after creating mount points and setting up the ssh keys and the ssh config file):
sshfs crin1:/ /media/crin1/ sshfs crin2:/ /media/crin2/ sshfs crin4:/ /media/crin4/
A new bucket was created for each server, at Advania eg:
- crin1
- crin2
- crin4
File systems were created:
mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 s3c://s.qstack.advania.com:443/crin1 mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 s3c://s.qstack.advania.com:443/crin2 mkfs.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 s3c://s.qstack.advania.com:443/crin4
The /root/.s3ql/authinfo2 file was edited following the documentation:
[s3c] storage-url: s3c://s.qstack.advania.com:443/ backend-login: XXX backend-password: XXX [crin1] storage-url: s3c://s.qstack.advania.com:443/crin1 fs-passphrase: XXX [crin2] storage-url: s3c://s.qstack.advania.com:443/crin2 fs-passphrase: XXX [crin4] storage-url: s3c://s.qstack.advania.com:443/crin4 fs-passphrase: XXX
Create directories for mounting the S3QL filesystem, /media/s3ql/crin1 etc. and mount:
mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root s3c://s.qstack.advania.com:443/crin1 /media/s3ql/crin1 mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root s3c://s.qstack.advania.com:443/crin2 /media/s3ql/crin2 mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root s3c://s.qstack.advania.com:443/crin4 /media/s3ql/crin4
That seems fine, unmount them again:
umount.s3ql /media/s3ql/crin1 umount.s3ql /media/s3ql/crin2 umount.s3ql /media/s3ql/crin4
Previously scripts written for GreenQloud were use to mount the directories and run the backups, but since there is a s3_backup.sh script this was copied to /usr/local/bin/s3ql_backup and amended so the server / bucket can be passed to it on the command line and also so it reads a list of directories to backup from a file:
#!/bin/bash
# Abort entire script if any command fails
set -e
# This script assumes that bucketname and directory under
# /media match and is also assumes that a file, with the
# same name with a list of directories to backup exists
# in /etc/s3ql
# Check for bucket name / directory on standard input
if [[ $1 ]]; then
BUCKET=$1
elif [[ ! $1 ]]; then
echo "Type the bucketname and then [ENTER]:"
read bucket
BUCKET=$bucket
fi
# Backup destination (storage url)
storage_url="s3c://s.qstack.advania.com:443/$BUCKET"
# Check that a list of diectories to backup exists at
# /etc/s3ql/$BUCKET
if [[ ! -f "/etc/s3ql/$BUCKET" ]]; then
echo "You need to create /etc/s3ql/$BUCKET with a list of directories to backup"
exit
else
BACKUP_LIST="/etc/s3ql/$BUCKET"
fi
# Recover cache if e.g. system was shut down while fs was mounted
fsck.s3ql --batch "$storage_url"
# Create a temporary mountpoint and mount file system
mountpoint="/tmp/s3ql_backup_$$"
mkdir "$mountpoint"
mount.s3ql "$storage_url" "$mountpoint"
# Make sure the file system is unmounted when we are done
# Note that this overwrites the earlier trap, so we
# also delete the lock file here.
trap "cd /; umount.s3ql '$mountpoint'; rmdir '$mountpoint'; rm '$lock'" EXIT
# Figure out the most recent backup
cd "$mountpoint"
last_backup=`python <<EOF
import os
import re
backups=sorted(x for x in os.listdir('.') if re.match(r'^[\\d-]{10}_[\\d:]{8}$', x))
if backups:
print backups[-1]
EOF`
# Duplicate the most recent backup unless this is the first backup
new_backup=`date "+%Y-%m-%d_%H:%M:%S"`
if [ -n "$last_backup" ]; then
echo "Copying $last_backup to $new_backup..."
s3qlcp "$last_backup" "$new_backup"
# Make the last backup immutable
# (in case the previous backup was interrupted prematurely)
s3qllock "$last_backup"
fi
# ..and update the copy
#rsync -aHAXx --delete-during --delete-excluded --partial -v \
# --exclude /.cache/ \
# --exclude /.s3ql/ \
# --exclude /.thumbnails/ \
# --exclude /tmp/ \
# "/home/my_username/" "./$new_backup/"
if [[ -d $mountpoint ]]; then
if [[ ! -d "$mountpoint/$new_backup" ]]; then
echo "$mountpoint/$new_backup doesn't exist so creating it"
mkdir $mountpoint/$new_backup
fi
for dir in $(<${BACKUP_LIST}); do
mkdir "$mountpoint/$new_backup$dir/"
rsync -aHAXx --delete-during --delete-excluded --partial -v "/media/$BUCKET$dir/" "$mountpoint/$new_backup$dir/"
done
else
echo "$mountpoint doesn't exist - something has gone horribly wrong"
exit
fi
# Make the new backup immutable
s3qllock "$new_backup"
# Expire old backups
# Note that expire_backups.py comes from contrib/ and is not installed
# by default when you install from the source tarball. If you have
# installed an S3QL package for your distribution, this script *may*
# be installed, and it *may* also not have the .py ending.
expire_backups --use-s3qlrm 1 7 14 31 90 180 360
And it was tested for Crin4 (unique strings have been replaced with XXX):
s3ql_backup crin4
Starting fsck of s3c://s.qstack.advania.com:443/crin4/
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
Checking objects (sizes)...
Checking blocks (referenced objects)...
Checking blocks (refcounts)...
Checking blocks (checksums)...
Checking inode-block mapping (blocks)...
Checking inode-block mapping (inodes)...
Checking inodes (refcounts)...
Checking inodes (sizes)...
Checking extended attributes (names)...
Checking extended attributes (inodes)...
Checking symlinks (inodes)...
Checking directory reachability...
Checking unix conventions...
Checking referential integrity...
Dropping temporary indices...
Dumping metadata...
..objects..
..blocks..
..inodes..
..inode_blocks..
..symlink_targets..
..names..
..contents..
..ext_attributes..
Compressing and uploading metadata...
Wrote 217 bytes of compressed metadata.
Cycling metadata backups...
Backing up old metadata...
Unexpected server reply: expected XML, got:
200 OK
x-amz-meta-006: 'object_id': 's3ql_metadata_bak_1',
x-amz-meta-007: 'encryption': 'AES_v2',
Content-Length: 0
x-amz-meta-005: 'signature': b'XXX=',
x-amz-meta-002: 'nonce': b'XXX=',
x-amz-meta-003: 'compression': 'None',
x-amz-meta-000: 'data': b'XXX
x-amz-meta-001: Hqdkxrg8Pk5zw==',
x-amz-id-2: XXX
x-amz-meta-md5: XXX
x-amz-meta-004: 'format_version': 2,
Last-Modified: Thu, 23 Jul 2015 11:09:01 GMT
ETag: "XXX"
x-amz-request-id: XXX
x-amz-meta-format: raw2
Content-Type: text/html; charset="UTF-8"
X-Trans-Id: XXX
Date: Thu, 23 Jul 2015 11:09:00 +0000
Connection: keep-alive
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.13', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1307, in main
cycle_metadata(backend)
File "/usr/lib/s3ql/s3ql/metadata.py", line 121, in cycle_metadata
cycle_fn("s3ql_metadata_bak_%d" % i, "s3ql_metadata_bak_%d" % (i + 1))
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 291, in copy
self._copy_or_rename(src, dest, rename=False, metadata=metadata)
File "/usr/lib/s3ql/s3ql/backends/comprenc.py", line 325, in _copy_or_rename
self.backend.copy(src, dest, metadata=meta_raw)
File "/usr/lib/s3ql/s3ql/backends/common.py", line 52, in wrapped
return method(*a, **kw)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 404, in copy
root = self._parse_xml_response(resp, body)
File "/usr/lib/s3ql/s3ql/backends/s3c.py", line 554, in _parse_xml_response
raise RuntimeError('Unexpected server response')
RuntimeError: Unexpected server response
Try mounting the S3QL space:
mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root s3c://s.qstack.advania.com:443/crin4 /media/s3ql/crin4 Using 2 upload threads (memory limited). Autodetected 65498 file descriptors available for cache entries Ignoring locally cached metadata (outdated). Backend reports that fs is still mounted elsewhere, aborting.
So, that is how to reproduce the problem... I was suggested on the ticket I opened that I email the s3ql list, so I have done that and I have also emailed Advania.
comment:31 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.2
- Total Hours changed from 13.93 to 14.13
Nikolaus, the S3QL developer, replied on the list:
Look for" dumb-copy" in the S3QL documentation. But note that this does not speak well for your storage provider. I recommend raising this issue with them instead of working around it in S3QL.
The reference for this is http://www.rath.org/s3ql-docs/backends.html#cmdoption-s3c_backend-arg-dumb-copy but I'm not sure how to use this option:
mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root --dumb-copy s3c://s.qstack.advania.com:443/crin4 /media/s3ql/crin4
usage: mount.s3ql [-h] [--log <target>] [--cachedir <path>]
[--authfile <path>] [--debug-modules <modules>] [--debug]
[--quiet] [--backend-options <options>] [--version]
[--cachesize <size>] [--max-cache-entries <num>]
[--allow-other] [--allow-root] [--fg] [--upstart]
[--compress <algorithm-lvl>]
[--metadata-upload-interval <seconds>] [--threads <no>]
[--nfs]
<storage-url> <mountpoint>
mount.s3ql: error: unrecognized arguments: --dumb-copy
So I have asked on the s3ql list.
comment:32 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 2
- Total Hours changed from 14.13 to 16.13
So it's --backend-options=dumb-copy not --dumb-copy, trying again:
mount.s3ql --cachedir /var/s3ql --authfile /root/.s3ql/authinfo2 --allow-root --backend-options=dumb-copy s3c://s.qstack.advania.com:443/crin4 /media/s3ql/crin4 Using 2 upload threads (memory limited). Autodetected 65498 file descriptors available for cache entries Ignoring locally cached metadata (outdated). Backend reports that fs is still mounted elsewhere, aborting. umount.s3ql /media/s3ql/crin4 /media/s3ql/crin4 is not on an S3QL file system fsck.s3ql --backend-options=dumb-copy s3c://s.qstack.advania.com:443/crin4 Starting fsck of s3c://s.qstack.advania.com:443/crin4/ Using cached metadata. Remote metadata is outdated. Checking DB integrity... Creating temporary extra indices... Checking lost+found... Checking cached objects... Checking names (refcounts)... Checking contents (names)... Checking contents (inodes)... Checking contents (parent inodes)... Checking objects (reference counts)... Checking objects (backend)... Checking objects (sizes)... Checking blocks (referenced objects)... Checking blocks (refcounts)... Checking blocks (checksums)... Checking inode-block mapping (blocks)... Checking inode-block mapping (inodes)... Checking inodes (refcounts)... Checking inodes (sizes)... Checking extended attributes (names)... Checking extended attributes (inodes)... Checking symlinks (inodes)... Checking directory reachability... Checking unix conventions... Checking referential integrity... Dropping temporary indices... Dumping metadata... ..objects.. ..blocks.. ..inodes.. ..inode_blocks.. ..symlink_targets.. ..names.. ..contents.. ..ext_attributes.. Compressing and uploading metadata... Wrote 217 bytes of compressed metadata. Cycling metadata backups... Backing up old metadata... Completed fsck of s3c://s.qstack.advania.com:443/crin4/
So that seems to work... the backup script, /usr/local/bin/s3ql_backup was updated:
#!/bin/bash
# Abort entire script if any command fails
set -e
# This script assumes that bucketname and directory under
# /media match and is also assumes that a file, with the
# same name with a list of directories to backup exists
# in /etc/s3ql
# Check for bucket name / directory on standard input
if [[ $1 ]]; then
BUCKET=$1
elif [[ ! $1 ]]; then
echo "Type the bucketname and then [ENTER]:"
read bucket
BUCKET=$bucket
fi
# Backup destination (storage url)
storage_url="s3c://s.qstack.advania.com:443/$BUCKET"
# Check that a list of diectories to backup exists at
# /etc/s3ql/$BUCKET
if [[ ! -f "/etc/s3ql/$BUCKET" ]]; then
echo "You need to create /etc/s3ql/$BUCKET with a list of directories to backup"
exit
else
BACKUP_LIST="/etc/s3ql/$BUCKET"
fi
# Recover cache if e.g. system was shut down while fs was mounted
fsck.s3ql --backend-options="dumb-copy" --batch "$storage_url"
# Create a temporary mountpoint and mount file system
mountpoint="/tmp/s3ql_backup_$$"
mkdir "$mountpoint"
mount.s3ql --backend-options="dumb-copy" "$storage_url" "$mountpoint"
# Make sure the file system is unmounted when we are done
# Note that this overwrites the earlier trap, so we
# also delete the lock file here.
trap "cd /; umount.s3ql '$mountpoint'; rmdir '$mountpoint'; rm '$lock'" EXIT
# Figure out the most recent backup
cd "$mountpoint"
last_backup=`python <<EOF
import os
import re
backups=sorted(x for x in os.listdir('.') if re.match(r'^[\\d-]{10}_[\\d:]{8}$', x))
if backups:
print backups[-1]
EOF`
# Duplicate the most recent backup unless this is the first backup
new_backup=`date "+%Y-%m-%d_%H:%M:%S"`
if [ -n "$last_backup" ]; then
echo "Copying $last_backup to $new_backup..."
s3qlcp "$last_backup" "$new_backup"
# Make the last backup immutable
# (in case the previous backup was interrupted prematurely)
s3qllock "$last_backup"
fi
# ..and update the copy
#rsync -aHAXx --delete-during --delete-excluded --partial -v \
# --exclude /.cache/ \
# --exclude /.s3ql/ \
# --exclude /.thumbnails/ \
# --exclude /tmp/ \
# "/home/my_username/" "./$new_backup/"
if [[ -d $mountpoint ]]; then
if [[ ! -d "$mountpoint/$new_backup" ]]; then
echo "$mountpoint/$new_backup doesn't exist so creating it"
mkdir -p $mountpoint/$new_backup
fi
for dir in $(<${BACKUP_LIST}); do
mkdir -p "$mountpoint/$new_backup$dir/"
rsync -aHAXx --delete-during --delete-excluded --partial -v "/media/$BUCKET$dir/" "$mountpoint/$new_backup$dir/"
done
else
echo "$mountpoint doesn't exist - something has gone horribly wrong"
exit
fi
# Make the new backup immutable
s3qllock "$new_backup"
# Expire old backups
# Note that expire_backups.py comes from contrib/ and is not installed
# by default when you install from the source tarball. If you have
# installed an S3QL package for your distribution, this script *may*
# be installed, and it *may* also not have the .py ending.
expire_backups --use-s3qlrm 1 7 14 31 90 180 360
Create a script to mount and un-mount the servers via SSHFS, wiki:SshfsMnt, create a wiki page for the backup script, wiki:S3QLBackup and one for a mount and unmount script, S3QLMnt
Testing the backup script for Crin1 ended with this message:
sent 556,338,946 bytes received 816,520 bytes 472,766.62 bytes/sec total size is 553,284,301 speedup is 0.99 Found more than one backup but no state file! Aborting.
I'm not sure what this means, it appears to still be running, it is an error message from /usr/bin/expire_backups.
The backup tasks were added to the Crin3 root crontab:
01 01 * * * umnt-s3ql crin1 ; mnt-sshfs crin1 ; s3ql_backup crin1 01 02 * * * umnt-s3ql crin2 ; mnt-sshfs crin2 ; s3ql_backup crin2 01 03 * * * umnt-s3ql crin4 ; mnt-sshfs crin4 ; s3ql_backup crin4
Exim was configured on Crin3:
dpkg-reconfigure exim4-config
And Also Fail2ban and Iptables were setup.
I have left the backup jobs running in screen, I'll check back on them later to see if they are working OK.
comment:33 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.71
- Total Hours changed from 16.13 to 16.84
The backup jobs seem to be running OK so far (but I did have to reboot the server last night after s3ql appeared to have stopped responding, as a result there are lots of inodes being committed to the backend during the s3ql filesystem check), I have done some work on the documentation, at Crin3 and have enabled a nightly cronjob to run the backups. We also now have Munin stats for the server.
comment:34 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.03
- Total Hours changed from 16.84 to 16.87
One issue that still need solving is the error from the expire_backups script:
Found more than one backup but no state file! Aborting.
comment:35 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.16
- Total Hours changed from 16.87 to 17.03
There is a problem with the Crin2 S3QL bucket:
fsck.s3ql --backend-options="dumb-copy" s3c://s.qstack.advania.com:443/crin2
Starting fsck of s3c://s.qstack.advania.com:443/crin2/
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 19000 objects so far..object 6236 only exists in table but not in backend, deleting
File may lack data, moved to /lost+found: b'/lost+found/lost+found_lost+found__2015-07-23________14:31:29____var____www____prod____docroot____owncloud________old____3rdparty____symfony____routing____Symfony____Component____Routing____Router.php'
Dropping temporary indices...
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.13', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1272, in main
fsck.check()
File "/usr/lib/s3ql/s3ql/fsck.py", line 90, in check
self.check_objects_id()
File "/usr/lib/s3ql/s3ql/fsck.py", line 951, in check_objects_id
(_, newname) = self.resolve_free(b"/lost+found", escape(path))
File "/usr/lib/s3ql/s3ql/fsck.py", line 1004, in resolve_free
name += b'-'
TypeError: Can't convert 'bytes' object to str implicitly
I have looked at the Advania interface and there isn't a way to delete all the files and start again as you just get a spinning progress bar when you try to get the list of times in the bucket. Ill email Advania] about this.
comment:36 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.26
- Total Hours changed from 17.03 to 17.29
Someone else had this error in March 2014, I tried applying the patch and then got this error:
fsck.s3ql --backend-options="dumb-copy" s3c://s.qstack.advania.com:443/crin2
Starting fsck of s3c://s.qstack.advania.com:443/crin2/
Using cached metadata.
Remote metadata is outdated.
Checking DB integrity...
Creating temporary extra indices...
Checking lost+found...
Checking cached objects...
Checking names (refcounts)...
Checking contents (names)...
Checking contents (inodes)...
Checking contents (parent inodes)...
Checking objects (reference counts)...
Checking objects (backend)...
..processed 18000 objects so far..object 6236 only exists in table but not in backend, deleting
File may lack data, moved to /lost+found: b'/lost+found/lost+found_lost+found__2015-07-23________14:31:29____var____www____prod____docroot____owncloud________old____3rdparty____symfony____routing____Symfony____Component____Routing____Router.php'
Dropping temporary indices...
Uncaught top-level exception:
Traceback (most recent call last):
File "/usr/bin/fsck.s3ql", line 9, in <module>
load_entry_point('s3ql==2.13', 'console_scripts', 'fsck.s3ql')()
File "/usr/lib/s3ql/s3ql/fsck.py", line 1274, in main
fsck.check()
File "/usr/lib/s3ql/s3ql/fsck.py", line 90, in check
self.check_objects_id()
File "/usr/lib/s3ql/s3ql/fsck.py", line 951, in check_objects_id
(_, newname) = self.resolve_free(b"/lost+found", escape(path))
File "/usr/lib/s3ql/s3ql/fsck.py", line 1002, in resolve_free
name = b'%s ... %s' % (name[0:120], name[-120:])
TypeError: unsupported operand type(s) for %: 'bytes' and 'tuple'
I have raised this on the thread I created on the S3QL list.
comment:37 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.43
- Total Hours changed from 17.29 to 17.72
The Advania web interface is very slow, I expect, due to the number of files created in each bucket and doing something like deleting all the files in a bucket would take forever as each delete takes two clicks, so installing s3cmd:
aptitude install s3cmd
Create a /root/.s3cfg file like this:
[default] access_key = XXX host_base = s.qstack.advania.com:443 host_bucket = %(bucket)s.s.qstack.advania.com:443 secret_key = XXX use_https = True signature_v2 = True
Then this can be used to list buckets etc, eg:
s3cmd ls 2009-02-03 16:45 s3://crin-1984-crin1 2009-02-03 16:45 s3://crin-1984-crin2 2009-02-03 16:45 s3://crin-gq-db1 2009-02-03 16:45 s3://crin-gq-web1 2009-02-03 16:45 s3://crin-gq-web2 2009-02-03 16:45 s3://crin-gq-wiki 2009-02-03 16:45 s3://crin-greenqloud-db1 2009-02-03 16:45 s3://crin1 2009-02-03 16:45 s3://crin2 2009-02-03 16:45 s3://crin4 2009-02-03 16:45 s3://crinbackup-default
So deleting the buckets we don't need:
s3cmd del s3://crin-gq-wiki/* File s3://crin-gq-wiki/s3ql_data_10 deleted File s3://crin-gq-wiki/s3ql_data_100 deleted File s3://crin-gq-wiki/s3ql_data_1000 deleted ... s3cmd rb s3://crin-gq-wiki
Note in one bucket there was a hidden ~/.trash directory which needed all the files manually deleting via the web interface, I have set off lots of sessions in screen to delete the corrupted data and buckets we don't need (everything apart from crin1 and crin4) as these commands take a long time to run...
comment:38 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Total Hours changed from 17.72 to 17.87
Looking at the volume of files deleted in around 20 mins:
date ; s3cmd du -H Fri Jul 24 21:49:57 GMT 2015 12G s3://crin-gq-web1/ 62M s3://crin-gq-web2/ 1444M s3://crin1/ 492M s3://crin2/ 322M s3://crin4/ 0 s3://crinbackup-default/ -------- 14G Total date ; s3cmd du -H Fri Jul 24 22:11:50 GMT 2015 12G s3://crin-gq-web1/ 59M s3://crin-gq-web2/ 1444M s3://crin1/ 484M s3://crin2/ 322M s3://crin4/ 0 s3://crinbackup-default/ -------- 14G Total
It'll take around 20 hours to delete the files in crin2 (8M in 20 mins so 24M an hour and 484/24 is 20) and days to delete crin-gq-web1.
comment:39 follow-up: ↓ 40 Changed 3 years ago by jenny
Hi Chris,
Please can you confirm that the deletions would be automated rather than you spending 20 hours on these. This would be way outside our budget. I see that the ticket for this has already crept up to 18 hours. Are the deletions the final step?
Thanks,
Jenny
Sent from my iPhone
> On 24 Jul 2015, at 23:44, CRIN Trac <trac@trac.crin.org> wrote:
>
> #11: Set up backups
> -------------------------------------+-------------------------------------
> Reporter: chris | Owner: chris
> Type: defect | Status: reopened
> Priority: major | Milestone: Install and
> | configure crin1
> Component: backups | Version:
> Resolution: | Keywords:
> Estimated Number of Hours: 6 | Add Hours to Ticket: 0.15
> Billable?: 1 | Total Hours: 17.72
> -------------------------------------+-------------------------------------
> Changes (by chris):
>
> * hours: 0 => 0.15
> * totalhours: 17.72 => 17.87
>
>
> Comment:
>
> Looking at the volume of files deleted in around 20 mins:
>
> {{{
> date ; s3cmd du -H
> Fri Jul 24 21:49:57 GMT 2015
> 12G s3://crin-gq-web1/
> 62M s3://crin-gq-web2/
> 1444M s3://crin1/
> 492M s3://crin2/
> 322M s3://crin4/
> 0 s3://crinbackup-default/
> --------
> 14G Total
>
> date ; s3cmd du -H
> Fri Jul 24 22:11:50 GMT 2015
> 12G s3://crin-gq-web1/
> 59M s3://crin-gq-web2/
> 1444M s3://crin1/
> 484M s3://crin2/
> 322M s3://crin4/
> 0 s3://crinbackup-default/
> --------
> 14G Total
> }}}
>
> It'll take around 20 hours to delete the files in crin2 (8M in 20 mins so
> 24M an hour and 484/24 is 20) and days to delete crin-gq-web1.
>
> --
> Ticket URL: <https://trac.crin.org.archived.website/trac/ticket/11#comment:38>
> CRIN Trac <https://trac.crin.org.archived.website/trac>
> Trac project for CRIN website and servers.
comment:40 in reply to: ↑ 39 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.45
- Total Hours changed from 17.87 to 18.32
Replying to jenny:
Please can you confirm that the deletions would be automated rather than you spending 20 hours on these.
Yes of course, it would be too boring to watch it happening!
I see that the ticket for this has already crept up to 18 hours. Are the deletions the final step?
This ticket stood at 10h 58m when I started work on it again, ticket:11#comment:29 so we are still under the 8 hour budget.
All the files were removed overnight so the unneeded buckets were deleted, the crin2 bucket was reformatted:
mkfs.s3ql --authfile /root/.s3ql/authinfo2 s3c://s.qstack.advania.com:443/crin2
And I have manually set off the backup of crin2.
The backups of crin1 and crin4 should have happened last night but didn't as /usr/local/bin isn't in the default path, the email:
Date: Sat, 25 Jul 2015 03:01:01 +0000 From: Cron Daemon <root@crin3.crin.org> To: root@crin3.crin.org Subject: Cron <root@crin3> umnt-s3ql crin4 ; mnt-sshfs crin4 ; s3ql_backup crin4 /bin/sh: 1: umnt-s3ql: not found /bin/sh: 1: mnt-sshfs: not found /bin/sh: 1: s3ql_backup: not found
So the crontab has been updated:
# m h dom mon dow command 01 01 * * * /usr/local/bin/umnt-s3ql crin1 ; /usr/local/bin/mnt-sshfs crin1 ; /usr/local/bin/s3ql_backup crin1 #01 02 * * * /usr/local/bin/umnt-s3ql crin2 ; /usr/local/bin/mnt-sshfs crin2 ; /usr/local/bin/s3ql_backup crin2 01 03 * * * /usr/local/bin/umnt-s3ql crin4 ; /usr/local/bin/mnt-sshfs crin4 ; /usr/local/bin/s3ql_backup crin4
This ticket is almost ready to be closed.
comment:41 Changed 3 years ago by chris
- Add Hours to Ticket changed from 0 to 0.15
- Resolution set to fixed
- Status changed from reopened to closed
- Total Hours changed from 18.32 to 18.47
The backups all ran fine last night, deleting old backups can be left to a later date as we will want to keep at least 30 days worth.
The backup space being used:
s3cmd du -H 1981M s3://crin1/ 17G s3://crin2/ 625M s3://crin4/
Closing this ticket, other tickets can be opened as needs be in the future for things like removing old backups.
The Advania Qstack interface requires 3rd party cookies to be enabled before you can login, it tooks a while to discover this. Their documentation for setting up encrypted S3QL storage is here:
Go to the Storage page:
Follow "Create new bucket", create crin-gq-db1 as a backup bucket for the current live database server, then on db1 the /root/.s3ql/authinfo2 file needs updating:
Delete the old files and create a filesystem:
And this generates an error:
Uncaught top-level exception. Traceback (most recent call last): File '/usr/bin/mkfs.s3ql', line 9, in <module>() load_entry_point('s3ql==1.11.1', 'console_scripts', 'mkfs.s3ql')() Current bindings: load_entry_point = <function load_entry_point> File '/usr/lib/s3ql/s3ql/mkfs.py', line 95, in main(args=['--cachedir', '/var/s3ql', '--authfile', '/root/.s3ql/authinfo2', '--ssl', 's3c://s.qstack.advania.com:443/crin-gq-db1']) plain_backend = get_backend(options, plain=True) Current bindings: plain_backend undefined get_backend = <function get_backend> (global) options = Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1') plain undefined builtinTrue = True (local) File '/usr/lib/s3ql/s3ql/backends/common.py', line 1103, in get_backend(options=Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1'), plain=True) return get_backend_factory(options, plain)() Current bindings: get_backend_factory = <function get_backend_factory> (global) options = Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1') plain = True File '/usr/lib/s3ql/s3ql/backends/common.py', line 1174, in get_backend_factory(options=Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1'), plain=True) _ = backend['s3ql_passphrase'] Current bindings: _ undefined backend = <s3ql.backends.s3c.Backend object> File '/usr/lib/s3ql/s3ql/backends/common.py', line 197, in __getitem__(self=<s3ql.backends.s3c.Backend object>, key='s3ql_passphrase') return self.fetch(key)[0] Current bindings: self = <s3ql.backends.s3c.Backend object> self.fetch = <bound method Backend.fetch of <s3ql.backends.s3c.Backend object>> (local) key = 's3ql_passphrase' File '/usr/lib/s3ql/s3ql/backends/common.py', line 250, in fetch(self=<s3ql.backends.s3c.Backend object>, key='s3ql_passphrase') return self.perform_read(do_read, key) Current bindings: self = <s3ql.backends.s3c.Backend object> self.perform_read = <bound method Backend.perform_read of <s3ql.backends.s3c.Backend object>> (local) do_read = <function do_read> key = 's3ql_passphrase' File '/usr/lib/s3ql/s3ql/backends/common.py', line 61, in wrapped(self=<s3ql.backends.s3c.Backend object>, *a=(<function do_read>, 's3ql_passphrase'), **kw={}) return fn(self, *a, **kw) Current bindings: fn = <function perform_read> self = <s3ql.backends.s3c.Backend object> a = (<function do_read>, 's3ql_passphrase') kw = {} Uncaught top-level exception. Traceback (most recent call last): File '/usr/bin/mkfs.s3ql', line 9, in <module>() load_entry_point('s3ql==1.11.1', 'console_scripts', 'mkfs.s3ql')() Current bindings: load_entry_point = <function load_entry_point> File '/usr/lib/s3ql/s3ql/mkfs.py', line 95, in main(args=['--cachedir', '/var/s3ql', '--authfile', '/root/.s3ql/authinfo2', '--ssl', 's3c://s.qstack.advania.com:443/crin-gq-db1']) plain_backend = get_backend(options, plain=True) Current bindings: plain_backend undefined get_backend = <function get_backend> (global) options = Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1') plain undefined builtinTrue = True (local) File '/usr/lib/s3ql/s3ql/backends/common.py', line 1103, in get_backend(options=Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1'), plain=True) return get_backend_factory(options, plain)() Current bindings: get_backend_factory = <function get_backend_factory> (global) options = Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1') plain = True File '/usr/lib/s3ql/s3ql/backends/common.py', line 1174, in get_backend_factory(options=Namespace(authfile='/root/.s3ql/authinfo2', cach...url='s3c://s.qstack.advania.com:443/crin-gq-db1'), plain=True) _ = backend['s3ql_passphrase'] Current bindings: _ undefined backend = <s3ql.backends.s3c.Backend object> File '/usr/lib/s3ql/s3ql/backends/common.py', line 197, in __getitem__(self=<s3ql.backends.s3c.Backend object>, key='s3ql_passphrase') return self.fetch(key)[0] Current bindings: self = <s3ql.backends.s3c.Backend object> self.fetch = <bound method Backend.fetch of <s3ql.backends.s3c.Backend object>> (local) key = 's3ql_passphrase' File '/usr/lib/s3ql/s3ql/backends/common.py', line 250, in fetch(self=<s3ql.backends.s3c.Backend object>, key='s3ql_passphrase') return self.perform_read(do_read, key) Current bindings: self = <s3ql.backends.s3c.Backend object> self.perform_read = <bound method Backend.perform_read of <s3ql.backends.s3c.Backend object>> (local) do_read = <function do_read> key = 's3ql_passphrase' File '/usr/lib/s3ql/s3ql/backends/common.py', line 61, in wrapped(self=<s3ql.backends.s3c.Backend object>, *a=(<function do_read>, 's3ql_passphrase'), **kw={}) return fn(self, *a, **kw) Current bindings: fn = <function perform_read> self = <s3ql.backends.s3c.Backend object> a = (<function do_read>, 's3ql_passphrase') kw = {} File '/usr/lib/s3ql/s3ql/backends/common.py', line 223, in perform_read(self=<s3ql.backends.s3c.Backend object>, fn=<function do_read>, key='s3ql_passphrase') with self.open_read(key) as fh: Current bindings: self = <s3ql.backends.s3c.Backend object> self.open_read = <bound method Backend.open_read of <s3ql.backends.s3c.Backend object>> (local) key = 's3ql_passphrase' fh undefined File '/usr/lib/s3ql/s3ql/backends/common.py', line 61, in wrapped(self=<s3ql.backends.s3c.Backend object>, *a=('s3ql_passphrase',), **kw={}) return fn(self, *a, **kw) Current bindings: fn = <function open_read> self = <s3ql.backends.s3c.Backend object> a = ('s3ql_passphrase',) kw = {} File '/usr/lib/s3ql/s3ql/backends/s3c.py', line 281, in open_read(self=<s3ql.backends.s3c.Backend object>, key='s3ql_passphrase') resp = self._do_request('GET', '/%s%s' % (self.prefix, key)) Current bindings: resp undefined self = <s3ql.backends.s3c.Backend object> self._do_request = <bound method Backend._do_request of <s3ql.backends.s3c.Backend object>> (local) self.prefix = '' (local) key = 's3ql_passphrase' File '/usr/lib/s3ql/s3ql/backends/s3c.py', line 402, in _do_request(self=<s3ql.backends.s3c.Backend object>, method='GET', path='/s3ql_passphrase', subres=None, query_string=None, headers={'authorization': 'AWS XXX:XXX', 'connection': 'keep-alive', 'content-length': '0', 'date': 'Fri, 15 May 2015 13:19:22 GMT'}, body=None) raise HTTPError(resp.status, resp.reason, resp.getheaders(), resp.read()) Current bindings: HTTPError = <class 's3ql.backends.s3c.HTTPError'> (global) resp = <httplib.HTTPResponse instance> resp.status = 404 (local) resp.reason = 'Not Found' (local) resp.getheaders = <bound method HTTPResponse.getheaders of <httplib.HTTPResponse instance>> (local) resp.read = <bound method HTTPResponse.read of <httplib.HTTPResponse instance>> (local) Exception: HTTPError: 404 Not Found _set_retry_after = <bound method HTTPError._set_retry_after of HTTPError()> args = () body = "<?xml version='1.0' encoding='UTF-8'?>\n<Error><C...25a</RequestId><Key>s3ql_passphrase</Key></Error>" headers = [('x-amz-id-2', 'XXX'), ('transfer-encoding', 'chunked'), ('connection', 'keep-alive'), ('x-amz-request-id', 'XXX'), ('x-trans-id', 'XXX'), ('date', 'Fri, 15 May 2015 13:19:23 GMT'), ('content-type', 'text/xml')] message = '' msg = 'Not Found' retry_after = None status = 404Which I don't really understand, the URL is correct: https://s.qstack.advania.com/crin-gq-db1
Perhaps it is todo with the fact that db1 was set up to backup to GreenQloud's S3 storage, perhaps the Debian 7 (Wheezy) version of s3ql is too old, so trying to set it up on Crin1:
Add the following to /root/.s3ql/authinfo2:
Create the crin-1984-crin1 bucket at Advania and try to format the filesystem:
So try without --ssl:
That appears to work! The encryption passphrase was writen to /root/.s3ql/authinfo2 in this format:
Make a directory to mount the space and mount it:
So it looks like the format for the authfile has perhaps changed with this version of S3QL (the documentation I'm following was written for Debian 7 and we are on Debian 8 now).
But it works! I'll try some more to get it working on the GreenQloud servers but if it can't be then I could mount the GreenQloud servers onto the 1984.is servers via SFTP and then backup up to Advania from there, or perhaps I should compile a new version of S3QL or perhaps one from backports can be used, this will all have to wait till next week now.